Performing Named Entity Recognition on Historical Text to Build Historical Timelines
Capstone Project — CIS 9995
1. Problem & Motivation
Historians and researchers frequently need to extract key events, dates, and figures from large volumes of unstructured historical text. This project automates that process using Named Entity Recognition (NER) — a core NLP task that identifies and classifies entities such as people, organizations, locations, and dates within text.
Given a historical text as input, the system identifies all temporal entities, associates them with their contextual sentences, and produces a chronologically ordered timeline. Two deep learning architectures are implemented and compared against a SpaCy pretrained baseline.
2. System Architecture
┌──────────────┐ ┌──────────────────┐ ┌───────────────┐ ┌──────────────┐
│ Raw Text │────▶│ Preprocessing │────▶│ NER Model │────▶│ Timeline │
│ (OpenStax │ │ • Tokenization │ │ • DistilBERT │ │ Generation │
│ Textbook) │ │ • BIO Tagging │ │ • BiLSTM-CRF │ │ • Extract │
│ │ │ • Padding │ │ • SpaCy base │ │ • Sort │
└──────────────┘ └──────────────────┘ └───────────────┘ └──────────────┘
3. Methodology
3.1 Data Preparation
The training dataset consists of news articles processed through SpaCy's pretrained NER model to generate BIO-formatted labels. Each token is tagged with one of: B-DATE, I-DATE, B-PERSON, I-PERSON, B-GPE, I-GPE, B-ORG, I-ORG, and several other entity types, following the standard BIO (Begin-Inside-Outside) tagging scheme. The complete tag set consists of 37 tags. The testing dataset is drawn from five chapters of the U.S. History (OpenStax) textbook covering approximately 145 pages spanning the 1600s to the 1900s.
3.2 DistilBERT for Token Classification
A DistilBERT transformer encoder is fine-tuned with a dropout layer and linear classification head for token-level NER. Subword tokenization is handled via label alignment — only the first subword of each original word receives the ground-truth label; subsequent subwords are masked with -100 so they don't contribute to the loss. Training uses AdamW with linear warmup scheduling, gradient clipping, and early stopping based on validation F1.
3.3 BiLSTM-CRF
A Bidirectional LSTM with a Conditional Random Field (CRF) output layer. The input representation concatenates word embeddings with character-level CNN embeddings, capturing both semantic meaning and morphological features (useful for recognizing date patterns like "1848"). The CRF layer enforces valid BIO transition constraints during decoding via the Viterbi algorithm, preventing impossible tag sequences.
3.4 Timeline Generation
After NER inference, all tokens tagged as B-DATE / I-DATE are extracted and grouped into entity spans. A date parser extracts four-digit years from each span, handling formats including "1848", "March 1848", "July 4, 1776", and decade references. Each year is paired with its source sentence, deduplicated, and sorted chronologically.
4. Results
4.1 Training Loss Curves
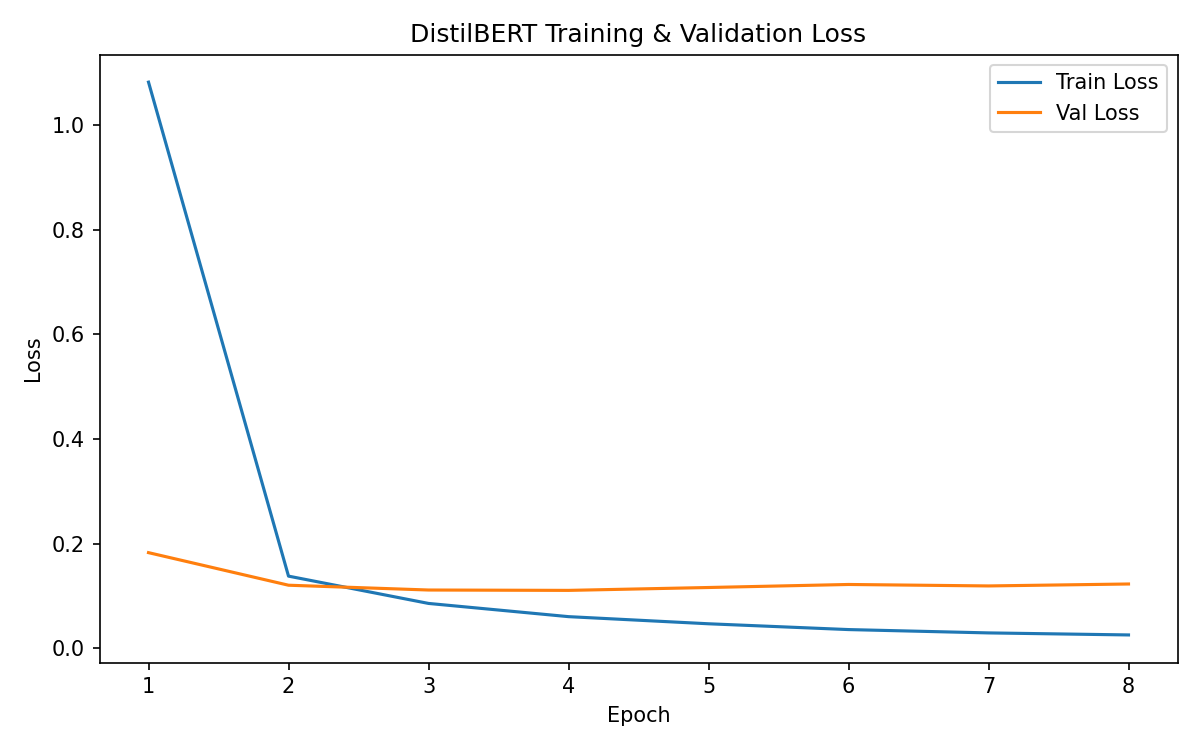
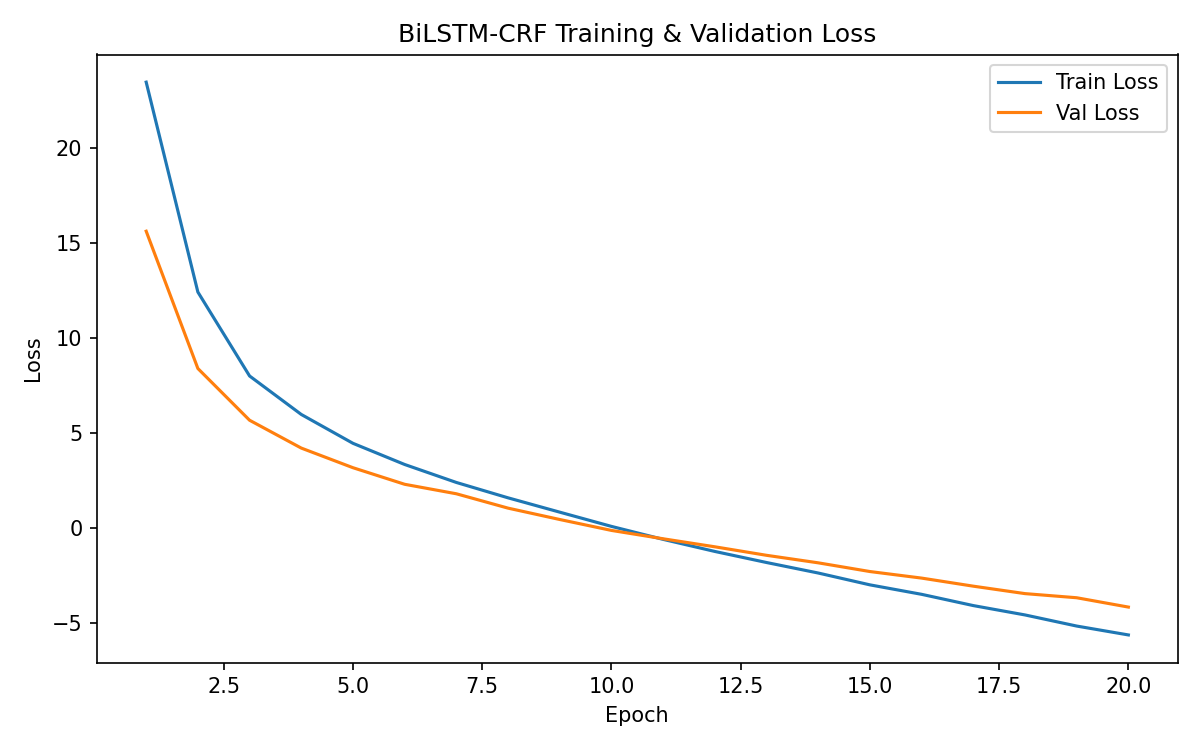
4.2 Timeline Evaluation
79/79
DistilBERT: Years Found
77/79
BiLSTM-CRF: Years Found
100%
All Timelines Sorted Correctly
| Model | Entries | Years | Precision | Recall | F1 | Sorted |
|---|---|---|---|---|---|---|
| SpaCy (baseline) | 420 | 79/79 | 1.000 | 1.000 | 1.000 | Yes |
| DistilBERT | 473 | 79/79 | 1.000 | 1.000 | 1.000 | Yes |
| BiLSTM-CRF | 439 | 77/79 | 1.000 | 0.975 | 0.987 | Yes |
DistilBERT matched SpaCy perfectly on year coverage and produced even more timeline entries (473 vs. 420), capturing additional contextual sentences per date. The BiLSTM-CRF achieved an F1 of 0.987 with perfect precision, missing only 2 of 79 years.
4.3 Sample Timeline Output
1848Women had first formulated their demand for the right to vote in the Declaration of Sentiments at a convention in Seneca Falls, New York in 1848...
1859Charles Darwin had first published his theory of natural selection in 1859...
1890In his book How the Other Half Lives (1890), journalist Jacob Riis used photojournalism to capture the dismal living conditions in working-class tenements...
1895In a speech at the Cotton States and International Exposition in Atlanta in 1895, Washington proposed what came to be known as the Atlanta Compromise...
1898Congress received McKinley's war message and on April 19, 1898, they officially recognized Cuba's independence...
5. Key Improvements
| Aspect | Previous | Current |
|---|---|---|
| Tagging Scheme | Flat tags (PERSON, DATE, O) | BIO scheme (B-DATE, I-DATE, O) |
| DistilBERT | Basic linear head | Dropout + warmup scheduler + subword alignment |
| LSTM Model | 2 training examples, no CRF | Full BiLSTM-CRF with char-CNN embeddings |
| Evaluation | Manual comparison of ~10 dates | Automated metrics on 420+ entries |
| Date Parsing | Only YYYY format | Multiple formats, decade references |
| Code | Notebooks with hardcoded paths | Modular Python package with config |
6. How to Run
# Install dependencies pip install -r requirements.txt python -m spacy download en_core_web_sm # Full pipeline (train + generate + evaluate) python run_all.py # SpaCy baseline only (no GPU needed) python run_all.py --spacy-only # Run steps individually python utils/preprocessing.py python train_distilbert.py python train_bilstm.py python generate_timeline.py python evaluate_models.py
7. Project Files
config.pyHyperparameters and pathsmodels/distilbert_ner.pyDistilBERT token classification modelmodels/bilstm_crf.pyBiLSTM-CRF with character CNNutils/preprocessing.pyData loading, BIO tagging, datasetsutils/evaluation.pyseqeval-based NER metrics + timeline metricsutils/timeline.pyEntity extraction and chronological orderingtrain_distilbert.pyTraining script for DistilBERTtrain_bilstm.pyTraining script for BiLSTM-CRFgenerate_timeline.pyInference and timeline generationevaluate_models.pyModel comparison and reportrun_all.pyEnd-to-end pipelinedata/Training and testing datasetsoutputs/Generated timelines and evaluation reports
8. Report & Source Code
Project Report (PDF): Download Report
Source Code: GitHub Repository
9. References
Chang, A. X. & Manning, C. D. (2012). SUTime: A Library for Recognizing and Normalizing Time Expressions. LREC 2012.
Devlin, J., Chang, M., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL 2019.
Huang, Z., Xu, W., & Yu, K. (2015). Bidirectional LSTM-CRF Models for Sequence Tagging. arXiv:1508.01991.
Lafferty, J., McCallum, A., & Pereira, F. (2001). Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. ICML 2001.
Sanh, V., Debut, L., Chaumond, J., & Wolf, T. (2019). DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv:1910.01108.
Stroetgen, J. & Gertz, M. (2012). Temporal Tagging on Different Domains: Challenges, Strategies, and Gold Standards. LREC 2012.